系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
Pytorch深度学习-----DataLoader的用法
Pytorch深度学习-----神经网络的基本骨架-nn.Module的使用
Pytorch深度学习-----神经网络的卷积操作
Pytorch深度学习-----神经网络之卷积层用法详解
Pytorch深度学习-----神经网络之池化层用法详解及其最大池化的使用
Pytorch深度学习-----神经网络之非线性激活的使用(ReLu、Sigmoid)
Pytorch深度学习-----神经网络之线性层用法
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
Pytorch深度学习-----损失函数(L1Loss、MSELoss、CrossEntropyLoss)
Pytorch深度学习-----优化器详解(SGD、Adam、RMSprop)
Pytorch深度学习-----现有网络模型的使用及修改(VGG16模型)
Pytorch深度学习-----神经网络模型的保存与加载(VGG16模型)
Pytorch深度学习-----完整神经网络模型训练套路
文章目录
- 系列文章目录
- 一、cpu上训练和gpu上训练两者的区别
- 二、进行gpu训练的方法步骤
- 1.检查GPU是否可用,并将其作为计算设备(device)。
- 2.将模型移动到GPU上
- 3.将数据(imgs和targets)也移动到GPU上。
- 4.将损失函数转移到device上去
- 三、代码
- 四、总结
一、cpu上训练和gpu上训练两者的区别
计算速度: GPU在并行计算上具有显著优势。相比于CPU,GPU拥有更多的计算核心,可以同时执行多个计算任务。神经网络的训练过程包含大量的矩阵运算和卷积操作,这些操作在GPU上可以并行计算,从而加速整个训练过程。CPU的计算能力较低,无法进行如此大规模的并行计算,导致在训练大型神经网络时速度较慢。
内存容量: GPU通常拥有更大的内存容量,可以存储和处理更大的数据集。在深度学习中,通常需要加载大量的训练数据,并将其保存在内存中以供模型训练使用。GPU的大内存容量可以容纳更多的数据,从而支持训练更大规模的模型。而CPU的内存容量相对较小,限制了可以处理的数据量。
并行性支持: GPU的架构被设计用于高度并行计算,这与神经网络的计算需求完美契合。神经网络中的许多计算操作,如矩阵乘法和卷积运算,可以通过并行计算在GPU上高效执行。GPU的并行计算能力使得神经网络在训练过程中能够同时处理多个数据样本,提高了训练速度。而在CPU上,由于较少的计算核心和较低的内存带宽,无法实现如此高效的并行计算。
总之,使用GPU进行神经网络模型训练相对于CPU具有更快的计算速度、更大的内存容量和更好的并行性支持。这使得GPU成为深度学习领域的重要工具,能够加速模型训练过程,处理更大规模的数据和网络。然而,对于一些小型模型和较小规模的数据集,使用CPU进行训练仍然是可行的选择。
二、进行gpu训练的方法步骤
以下步骤针对上一章节Pytorch深度学习-----完整神经网络模型训练套路里的代码进行总结
1.检查GPU是否可用,并将其作为计算设备(device)。
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
使用上述代码后如果可以用就是gpu进行训练,不可以用就是要cpu。
2.将模型移动到GPU上
通过调用to(device)方法将模型的参数和缓冲区移动到指定的设备上。
# 将模型移动到GPU上
lgl = lgl.to(device)
3.将数据(imgs和targets)也移动到GPU上。
在迭代训练和测试数据之前,将数据(imgs和targets)也移动到GPU上。
# 将数据移动到GPU上
imgs = imgs.to(device)
targets = targets.to(device)
4.将损失函数转移到device上去
# 将损失函数转换到device上去
loss_fn = loss_fn.to(device)
三、代码
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 加载自己搭建的神经网络
from model import *
'''
检查gpu是否可以用,并定义设备
'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
"""
1.数据集加载
"""
# 准备训练数据集
train_data = torchvision.datasets.CIFAR10(root="dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
# 准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 训练数据集的长度
train_data_sise = len(train_data)
print("训练数据集的长度为:{}".format(train_data_sise))
# 测试数据集的长度
test_data_sise = len(test_data)
print("测试数据集的长度:{}".format(test_data_sise))
# 加载数据集
train_dataloader = DataLoader(test_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
"""
2.模型的创建,这里直接from model import * 故下面直接调用
"""
# 实例化网络模型
lgl = Lgl()
'''
将模型移动到GPU上
'''
lgl = lgl.to(device)
"""
3.损失函数和优化器
"""
# 定义交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
'''
# 将损失函数转换到device上去
'''
loss_fn = loss_fn.to(device)
# 进行优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(lgl.parameters(), lr=learning_rate)
"""
4.训练循环步骤
4.1 为训练做的参数准备工作
"""
# 开始设置训练神经网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 记录是第几轮训练
epoch = 10
# 添加Tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("----第{}轮训练开始----".format(i))
"""
4.2 训练循环
"""
# 训练步骤
for data in train_dataloader:
'''
将数据(imgs和targets)也移动到GPU上
'''
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = lgl(imgs)
loos_result = loss_fn(outputs, targets)
# 优化器优化模型
# 将上一轮的梯度清零
optimizer.zero_grad()
# 借助梯度进行反向传播
loos_result.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loos_result.item()))
writer.add_scalar("train_loos", loos_result.item(), total_train_step)
"""
5.测试循环
"""
# 测试步骤开始
total_test_loos = 0
with torch.no_grad():
for imgs, targets in test_dataloader:
'''
将数据(imgs和targets)也移动到GPU上
'''
imgs = imgs.to(device)
targets = targets.to(device)
outputs = lgl(imgs)
loos_result = loss_fn(outputs, targets)
total_test_loos = total_test_loos + loos_result.item()
"""
6.测试过程的记录和输出
"""
print("整体测试集上损失函数loos:{}".format(total_test_loos))
writer.add_scalar("test_loos", total_test_loos, total_test_step)
total_test_step = total_test_step + 1
torch.save(lgl, "test_{}.pth".format(i))
print("模型已保存")
"""
7.结束训练步骤
"""
writer.close()
控制台
训练数据集的长度为:50000
测试数据集的长度:10000
----第0轮训练开始----
训练次数:100, loss:2.285776138305664
整体测试集上损失函数loos:358.6167891025543
模型已保存
----第1轮训练开始----
训练次数:200, loss:2.2544846534729004
训练次数:300, loss:2.2689497470855713
整体测试集上损失函数loos:353.03117847442627
模型已保存
----第2轮训练开始----
训练次数:400, loss:2.2088890075683594
整体测试集上损失函数loos:340.509489774704
模型已保存
----第3轮训练开始----
训练次数:500, loss:2.087219476699829
训练次数:600, loss:1.967397928237915
整体测试集上损失函数loos:348.03623950481415
模型已保存
----第4轮训练开始----
训练次数:700, loss:2.0620810985565186
整体测试集上损失函数loos:337.03663420677185
模型已保存
----第5轮训练开始----
训练次数:800, loss:1.952288031578064
训练次数:900, loss:1.8533779382705688
整体测试集上损失函数loos:323.8458157777786
模型已保存
----第6轮训练开始----
训练次数:1000, loss:1.8331818580627441
整体测试集上损失函数loos:310.2507711648941
模型已保存
----第7轮训练开始----
训练次数:1100, loss:1.924048662185669
训练次数:1200, loss:2.0032200813293457
整体测试集上损失函数loos:298.8608967065811
模型已保存
----第8轮训练开始----
训练次数:1300, loss:1.7624551057815552
训练次数:1400, loss:1.6117074489593506
整体测试集上损失函数loos:289.42032492160797
模型已保存
----第9轮训练开始----
训练次数:1500, loss:1.7228881120681763
整体测试集上损失函数loos:281.9151908159256
模型已保存
tensorboard面板
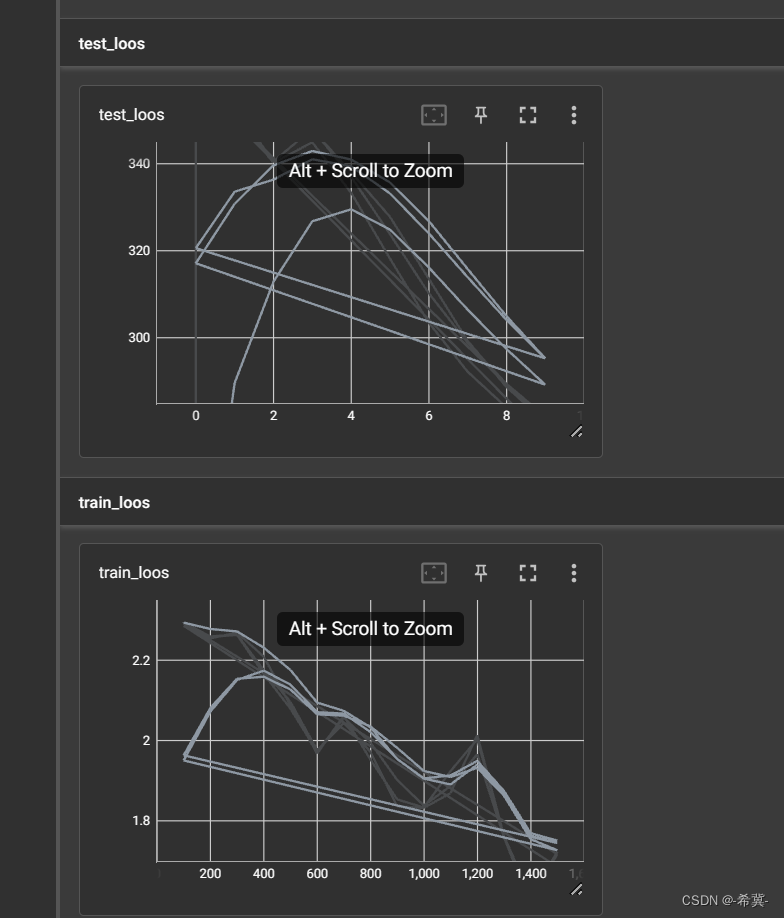
四、总结
在代码中,通过调用torch.device("cuda")来指定使用GPU进行计算。这是一种通用的方式,可以让PyTorch自动选择当前系统中的可用GPU。如果系统中有多个GPU可用,PyTorch将默认使用第一个可用的GPU作为计算设备。
如果你希望明确指定使用哪一块GPU,可以使用torch.device("cuda:0")来指定使用第一块GPU,或者使用torch.device("cuda:1")来指定使用第二块GPU,以此类推。例如,如果你的系统有两块GPU,你可以将以下代码用于指定使用第二块GPU:
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
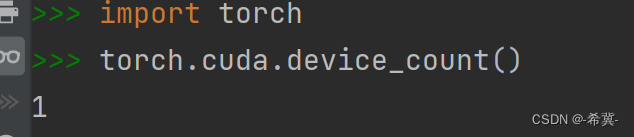
通过这种方式,你可以明确指定使用哪一块GPU来进行计算。需要注意的是,具体的GPU编号取决于系统中GPU的配置和可用情况,可以通过运行torch.cuda.device_count()来查看系统中可用的GPU数量以及它们的编号。